Numerous challenges faced worldwide can be effectively tackled through the applications of search, clustering, recommendation, or classification - all domains where embeddings excel. For instance, the task of locating research papers based on keywords becomes arduous when numerous synonymous terms exist. However, embeddings seamlessly simplify this process.
How does the process of obtaining embeddings work? To acquire embeddings, one must employ a pre-trained language model that encodes the given information into vector representations. It is normally follows a 4-step approach:
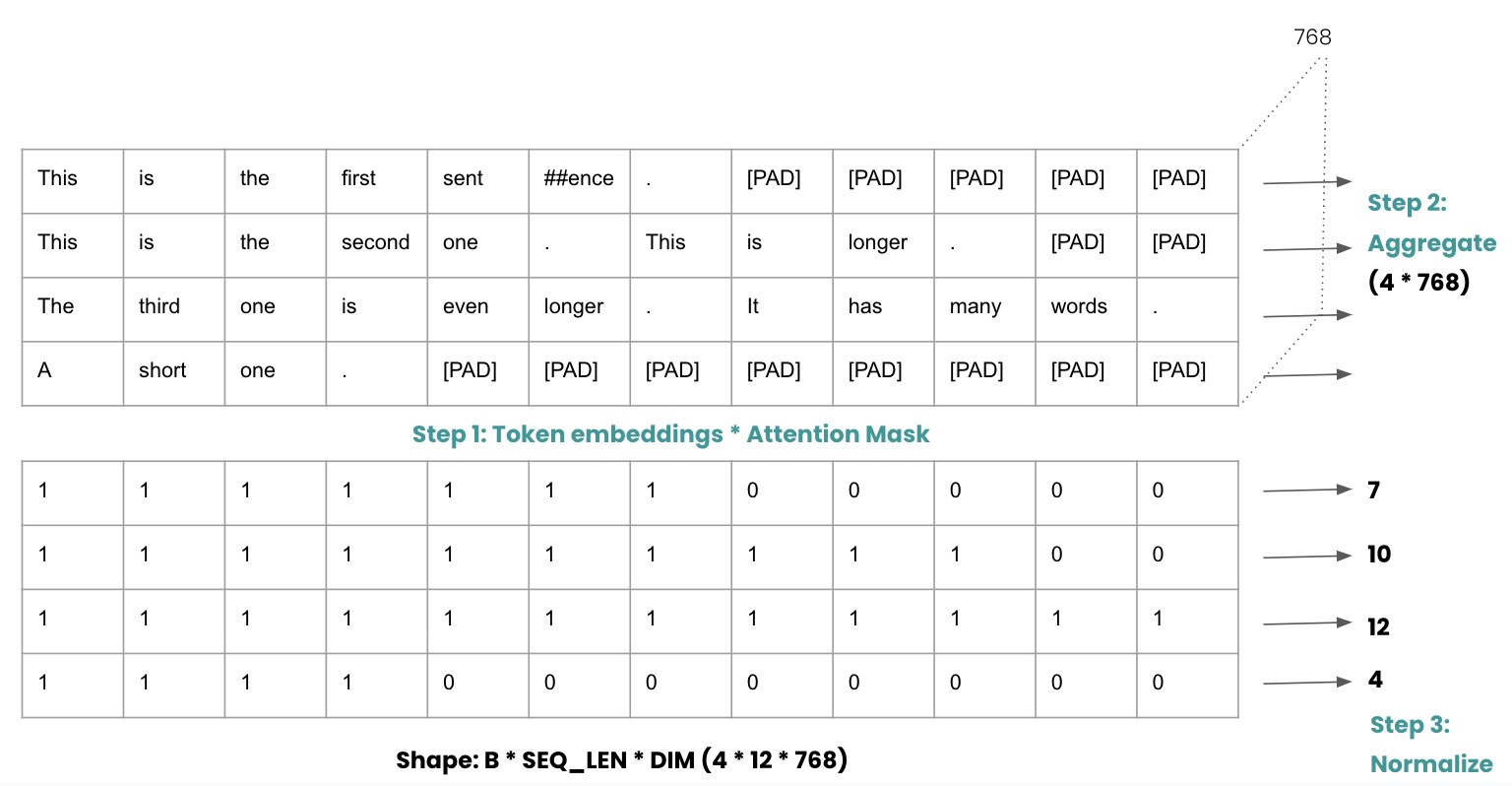
- Extract token embeddings and attention masks and multiply them. As illustrated in the example above, when dealing with a batch of 4 sentences, we apply padding to ensure they are of equal length, facilitating matrix computations. This results in an ndarray of size 4 * 12 * 768, with 768 representing the output embedding shape obtained from bert-base-uncased.
- Aggregate embeddings across all tokens within a sentence. This is accomplished by summing up the token embeddings along the appropriate axis. As a result, the size of the ndarray 4 * 12 * 768 is reduced to 4 * 768.
- Normalize the sentence embeddings by dividing them by the number of tokens present in the sentence (where the attention mask value is 1).
- Perform contrastive fine-tuning of the Language Model using tuples or triplets to bring similar items closer together and push dissimilar items apart.\
By leveraging the advancements of sbert and our specifically developed tool called Finetuner, you can make significant progress toward achieving this objective. However, this is still not enough:
- When the model size is small, it limits the quality of embeddings. In the year 2023, the bert-base-uncased model, which was developed in 2018 with 110 million parameters, is considered too small to meet current standards.
- Language models have a specific limit on the acceptable sequence length, which often results in truncating a significant portion of the sentence. For instance, the bert-base-uncased model can capture a maximum of 512 tokens, while the widely used minilm-l6-v2 can only accommodate a sequence length of 128.
- The existing embedding models are primarily developed using English corpora or unevenly distributed multilingual datasets. This can have potential implications for the usability of the embeddings.
OpenAI unveiled their latest embedding model, text-embedding-ada-002, in December 2022. This upgraded model boasts improved performance, a significantly reduced embedding size, and an expanded context length of 8192.
And we’re working on our own embeddings leveraging the recent development of LLMs.
2023 presents an ideal opportunity to kick-start the project due to the recent release of ChatGPT. The open-source community has been rapidly catching up, offering a wide range of open-source Language Models (LLMs) specifically designed for text generation. For instance:
- Pythia: a suit of LLMs from 70m to 12 billion and the 20 billion parameter GPT-NeoX.
- StableLM: a suit of LLMs from 3B to 65B (in progress).
- OpenLLaMA: a suit of LLMs from 3B to 13B.
- …
As a start-up, this implies that we are not obligated to invest millions of dollars in pre-training a Large Language Model. However, leverage the existing LLMs and employ contrastive fine-tuning techniques to enhance their performance.
So, where are we now?
Data
We have gathered a collection of 2 BILLION sentence pairs from various sources on the internet. These pairs have been harvested from diverse origins, including conversational data, query product pairs, question answering pairs and much more.
We have invested intensive efforts on cleaning the 2 billion sentence pairs, including (not limited to):
- Space removal.
- Re-shuffling and sharding.
- Duplicate removal.
- Near duplicate removal
- Language detection and remove non-english ones.
- Consistency filtering.
And we end-up with a high-quality dataset contains ~400 million sentence pairs, dedicated for training.
In addition to the dataset consisting of 400 million sentence pairs, we have curated an additional dataset of approximately 50,000 high-quality triplets. These triplets have been created using augmentation and generation techniques. The purpose of these specifically designed datasets is to address certain limitations present in existing off-the-shelf embedding models, such as handling negation. For instance, the phrases “the weather is nice” and “the weather is bad” clearly convey completely opposite meanings.
Loss
We are combining InBatchNegativeRankingLoss together with TripletMarginLoss for this,
following two training schemes:
- For the 400 million dataset, we utilize the
InBatchNegativeRankingLoss, followed by a second stage of fine-tuning using the 50,000 dataset employing theTripletMarginLoss. - The training process involves utilizing the
InBatchNegativeRankingLossfor several epochs, creating a checkpoint, transitioning to theTripletMarginLoss, creating another checkpoint, and then resuming training with theInBatchNegativeRankingLoss.
We have yet to establish which approach yields superior results; however, we anticipate obtaining conclusive findings in the near future.
Training
Given the fact that the 400 million sentence pair dataset are from different sources, to ensure the learning produce stable results, we employ the sharding and sampling approach:
Our training set consists of a collection of IterableDataset that are combined to form a ChainDataset. Each shard within the dataset comprises 100k sentence pairs, sampled sequentially from various sources. As a result, during each batch, when we select 2^n samples, they will all originate from dataset A. The subsequent batch will then exclusively comprise samples from dataset B, until the dataset get exhausted.
As stated before, we jointly utilize InBatchNegativeRankingLoss and TripletMarginLoss.
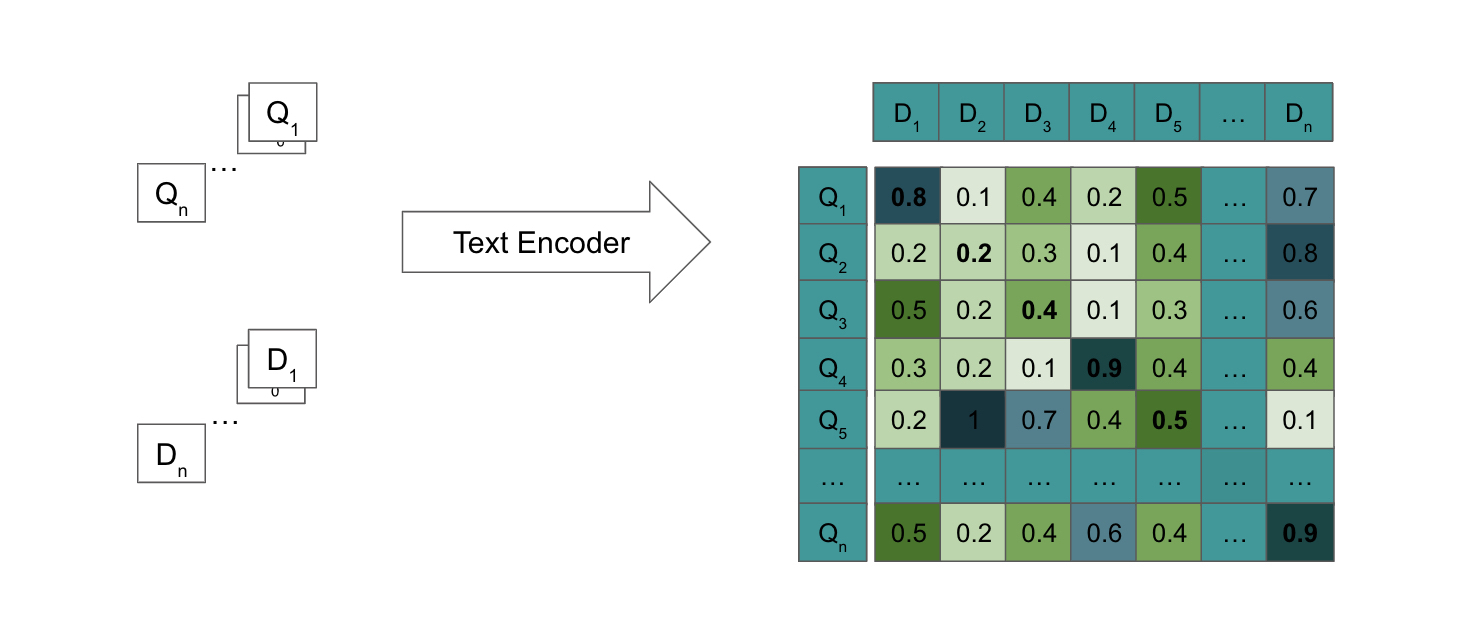
During the calculation of the loss, we implemented a filtering process to exclude the “easy negatives” within the batch. Specifically, we identified the Query Document pairs with similarity scores lower than the diagonal values and removed them from consideration.
Furthermore, rather than employing mean-pooling as previously introduced, we opted for weighted-mean-pooling. This approach assigns higher weights to later tokens in consideration of the causal attention mask present in an auto-regressive decoder transformer. Unlike an encoder transformer, tokens within a decoder transformer do not attend to future tokens.
For training such Language Models (LLMs), we utilized deepspeed stage 2 and employed mixed-precision (fp16). This combination enabled us to efficiently distribute optimizer states and gradients across multiple GPUs by partitioning them appropriately.
As the training process is still ongoing, a comprehensive evaluation has not yet been completed. However, during training, we incorporated MTEB (Massive Embedding Benchmark) as a callback function, enabling evaluation to be conducted at regular intervals, typically after every N batches.