Instance-level image retrieval is an important component of image retrieval tasks. Given an image as Query, an instance retrieval system aims at find the same objects D with respect to Q. For instance, given an image of the Great Wall, instance retrieval should be able to find other Great Wall images, under different circumstances. Or return facial images of the same person while querying with another facial image of a celebrity.
For a long period of time, (Supervised)Metric-Learning has always been the answer:
- Prepare a training set, with class labels.
- Construct triplets (or tuples, or more..), each triplet contains an anchor image, a positive and a negative.
- Apply triplet margin loss by maximizing the distance metric between anchor and negative pair, while pull anchor and positive closer.
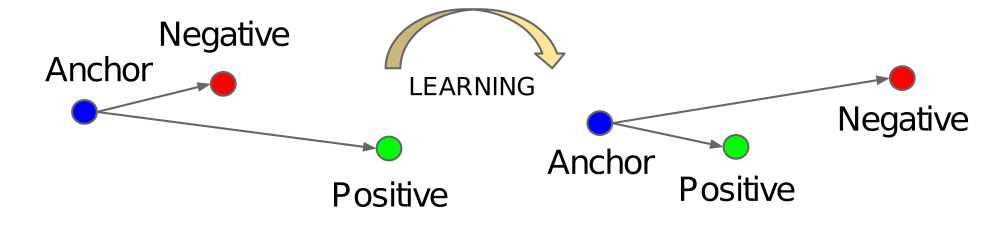 source: FaceNet: A Unified Embedding for Face Recognition and Clustering.
source: FaceNet: A Unified Embedding for Face Recognition and Clustering.
Apparently, supervised deep metric learning is more than that. In the past months, while developing Finetuner at Jina AI, we went through a lot of traps.
For instance, Should we allow user to manually create “hard-negatives”? The answer is a clear No. But in the first iteration, the input of our data is Document with 2 Matches like this:
| |
This “gives” user the power to perform manual positive/negative selection. However, does it make any sense? Probably not for several reasons:
- It takes efforts for users to perform negative mining, in another word, it take times.
- Since it might takes time, user might just randomly sampling negatives from other classes.
- Negative samples might not being effectively used. Suppose user select 1 positive 4 negatives, we end up with 4 triplets, not much, quantity wise.
- Negative samples might not being selected has hard-negatives, given in most cases, hard-negatives brings more benefits while model training.
What is the better approach? Do it automatically!
Suppose you have a deep metric learning training task, your batch size is 128, this is what we offer you:
- For each batch of 128 samples, we sample N items from the same class, e.g. 4. In the end, you got 32 classes within batch.
- Consider each item as an anchor image, then you get 3 positives (4 - 1).
- Consider each item as an anchor image, then you get 124 negatives (128 - 3 - 1).
- In the end, within this batch, how many triplets you get? Much larger than 4 if we perform manual negative selection (1 anchor-1 pos-4 neg)!
Now you have a set of triplets, you can either:
- Training your model with all automatically selected triplets (with no mining).
- Training your model with different mining strategies (easy/semi-hard/hard negative mining).
This makes training a metric learning model much more effectively. While you might still discover some minor issues:
If we want to apply hard-negative mining, and if I can only perform hard-negative mining within the batch, this means I can only select the “best” hard-negative within a batch, not over the entire dataset.
This is true, and 2 possible solutions: either you increase your batch size to generate a bigger “pool size” and reduce the issue, or you perform cross-batch hard-negative mining. Previous solution is easier, while could be limited by your hard-ware capacity. After all, GPU-memory is too limited compare with RAM. The later strategy, could resolve the issue. While it is tricky to bring the code into a reusable component of a software.
We’ve approved that deep metric learning + triplet margin loss + sampling + hard-negative mining is extremely useful, and, it is especially the case, for instance-level image retrieval.
Since 2018, Google launched Google Landmark Retrieval 2021. This is a perfect playground for instance-level image retrieval.
If you look at the top solutions, almost all of them use deep metric learning and some add-on tricks. Includes different loss functions, pooling layers etc. Nothing other than deep metric learning. The latest winner, according to leaderboard, reached a mAP@100 of 0.53751.
If you employ a pre-trained ResNet/EfficientNet trained on ImageNet dataset, remove the last classification layer and turn it into a Embedding model (feature extractor), you can get roughly 0.25 - 0.30 mAP@100. Quite significant improvement, right?
To now, we’ve discussed the basic idea of deep metric learning and how good it performs on Instance Retrieval task. You might ask, what about self-supervised learning (SSL), are you still going to mention that? I say yes, this is the turning point.
SSL has been a part of representation learning for some time. But we discovered significant progress has been made in the year of 2021. Such as SimCLR, SImCLRv2, MoCo, MocoV2, BYOL etc. These approaches aimes at learn a good representation (embedding model) with NO labels. AND THIS IS HUGE IN REAL-WORLD CASES.
As a machine learning engineer, How many times have you tried to convince your BOSS the importance of the labeling? How many times have you tried to label by yourself? Have you tried convince your manager to spend some money on crowdsourcing platforms to get labels for you? Are you tired of, build a user-in-the-loop pipeline to deploy a not-perfect model first, and expect to collect more labels as time pass by?
If non of above make any sense to you, good for you. But, what inspiring me most, is finally, we have a SSL paper evaluated on Instance Retrieval Task! This is published by facebook: Emerging Properties in Self-Supervised Vision Transformers. We’ll call it DINO in the following section. Let’s first see some evaluation result:
If you look at the results without reading the paper, it might confuse you. Basically, they trained the model on Google Landmark Dataset we mentioned above. While evaluated results on Oxford and Paris dataset (another 2 smaller version of landmark datasets). And they claim the results are even better than some supervised approaches.
How did they achieve it without using any labels?
Trick1: Multi-stage cropping. The basic idea of self-supervised learning is, given an image, it apply augmentation on this image two times, and generate 2 different Views of the same image. Even through these two different Views of the same image looks different, but we know they’re from the same classes: we augmented the image. Multi-stage cropping is another step: we crop the input image, let’s say 6 times. 2 times we use Global Cropping and we perform Local Cropping 4 times. Global cropping basically crops over 50% percent of the original image, while local cropping crops around 20-30% of the original image. After cropping, we transform the GlobalCropping back to 224 by 224, LocalCropping to 96 by 96.
Trick2: Patches and Vision Transformer. Once augmentation finished, we split the images into patches (a small portion of the augmented image). Feed patches as inputs to a Vision Transformer model. The final [CLS] token of 768d becomes the learned representation.
Trick3: Self-distillation and momentum update. Distillation normally involves 2 models, one smaller-sized student model and one larger sized teacher model. For DINO, the author used two identical models (ViT) for both student and teacher. While apply stop-gradient for teacher model (no back backpropagation), while update teacher model in an exponential moving average manner. EMA places a greater weight and significance on the most recent data points. At early stage, student network post a bit more significant impact on teacher networks’ parameters. As training goes on, the student network has less-and-less impact on teacher network, until training finish.
Trick4: Centering and Sharpening. According to previous SSL research, when training model with no negative samples (only tuples) can result in model collapse. The model can not distinguish which is good, which is bad since we only have positive samples. The author introduced Centering parameter C to keep the running average of the rated teacher network ouputs. And applied always deduct this running average when computing normalized cross-entropy loss.
How does is final representation looks like?

Training models without labels, for representation learning, evaluated on search task, and get very impressive results. These are the reasons I consider SSL could becomes a game changer.
How? It might change the way we deploy ML solutions for varies downstream tasks, such as search task. Currently, when user has limited amount of training data, the best situation seems to be: Use pre-trained model, freeze most of the layers, apply transfer learning + metric learning for model finetunning.
Suppose user provided large amount of messy training data without any labels, what can you do? The only possible way seems to be: combine Active Learning and Transfer Learning. User label the data interactively to provide labeled training samples. This could be useful, but lack of theoretical evaluations and practical support.
One would argue, in most of my use cases, I always have labeled data. This could be a valid point in today’s search industries. But to now, when applying deep learning on image retrieval, the market is super biased towards to fashion industry, and this industry, has a lot of labeled data already.
While I believe, with time pass by, we’ll soon see the shift of vector search from fashion, to more fields. Such as retail, tourism, real-estate, 3d meshes etc. Is our data/model ready for these industries already? The answer is clearly a no.
Think from another point, what if, the self-supervised learning approaches, without any supervision, could bring on-par performance compared with supervised approaches? It’s gonna an interesting case, then the only point for using metric-learning is because it’s faster and consume less time/power.
Stop from here. In the next blog, I’ll write another one brings more code and quantitative evaluation. We’ll get some better understanding of SSL vs Metric Learning by conducting some inspection on their failure cases.